Left Outer Join which we try to do
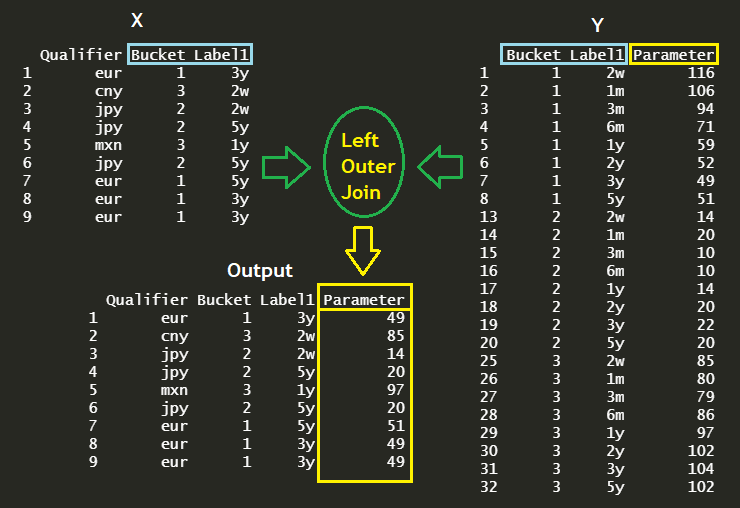
The following figure demonstrates what we are trying to do. The first is to perform left outer join for determining parameters for the corresponding Bucket and Label1, which are, in fact, currency volatility classification and maturity respectively. The second is to apply the original orders of row and column of x data to this merged result.
Read a data.frame from a String
It is typical to read data from Excel or csv file but for the purpose of quick and easy exercises, a string also can be read as a data.frame by using read.table() function. The following is to read x data.frame.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | # LEFT data which has joining key fields str.x <- "Qualifier Bucket Label1 eur 1 3y cny 3 2w jpy 2 2w jpy 2 5y mxn 3 1y jpy 2 5y eur 1 5y eur 1 3y eur 1 3y" x <- read.table(text=str.x, header = TRUE) --------------------------------------------- > x Qualifier Bucket Label1 1 eur 1 3y 2 cny 3 2w 3 jpy 2 2w 4 jpy 2 5y 5 mxn 3 1y 6 jpy 2 5y 7 eur 1 5y 8 eur 1 3y 9 eur 1 3y > | cs |
In this way, we can also read and make y_sc, y_dc data.frames. y_sc (y_dc) is a right data with same (different) key field (column) names.

Output of merge()
Using merge(), we can get the result of left outer join. There is no problem in this output and this result is generally recommended in a viewpoint of key columns.
In some case, it is somewhat inconvenient when we need the original orders of row and column for some reason because row and column of the result from merge() are rearranged in the following way.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # using merge() merge(x = x, y = y_sc, by.x = c("Bucket", "Label1"), by.y = c("Bucket", "Label1"), all.x = TRUE) -------------------------------------- > Bucket Label1 Qualifier Parameter 1 1 3y eur 49 2 1 3y eur 49 3 1 3y eur 49 4 1 5y eur 51 5 2 2w jpy 14 6 2 5y jpy 20 7 2 5y jpy 20 8 3 1y mxn 97 9 3 2w cny 85 > | cs |
Output with orders of row and column of left input data.frame
To preserve orders of the original row and column (of x data), we have only to track information of row and column of x data. For this purpose, we can make the following user-defined function(f_loj_krc()).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | #----------------------------------------------- # Function : f_loj_krc #----------------------------------------------- # Left outer join while keeping # orders of input rows and columns # Meaning of input arguments are # the same as those of merge() #----------------------------------------------- f_loj_krc <- function(x, y, by.x, by.y) { # save row id x.temp <- x; x.temp$temp.id <- 1:nrow(x.temp); # each column names x.cn <- colnames(x); y.cn <- colnames(y) # replace column names of y with same names of x # to avoid duplicate fields for(i in 1:length(by.y)) { colnames(y)[which(y.cn == by.y[i])] <- by.x[i] } # since two fields are the same now by.y <- by.x # new column names of y y.cn <- colnames(y) # remove only key fields which are redundant # and keep only new informative fields y.cn.not.key <- setdiff(y.cn, by.y) # left outer join df <- merge(x = x.temp, y = y, by.x=by.x, by.y=by.y, all.x = TRUE) # recover the original orders of row and column df <- df[order(df$temp.id),c(x.cn, y.cn.not.key)] rownames(df) <- NULL return(df) } | cs |
f_loj_krc() function keeps information of x data, uses merge() for left outer join, and recovers orders of the x's row and column. In particular, as x (left) and y (right) data may have either same or different key field names, we can replace key field names of y with those of x in case of two set of names are different. It's because it is preferable and parsimonious to remove redundant columns in merged output.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | # same key fields names between x and y f_loj_krc(x = x, y = y_sc, by.x=c("Bucket", "Label1"), by.y=c("Bucket", "Label1")) -------------------------------------- > Qualifier Bucket Label1 Parameter 1 eur 1 3y 49 2 cny 3 2w 85 3 jpy 2 2w 14 4 jpy 2 5y 20 5 mxn 3 1y 97 6 jpy 2 5y 20 7 eur 1 5y 51 8 eur 1 3y 49 9 eur 1 3y 49 > # different key fields names between x and y f_loj_krc(x = x, y = y_dc, by.x = c("Bucket", "Label1"), by.y = c("Bkt", "Lab1")) -------------------------------------- > Qualifier Bucket Label1 Parameter 1 eur 1 3y 49 2 cny 3 2w 85 3 jpy 2 2w 14 4 jpy 2 5y 20 5 mxn 3 1y 97 6 jpy 2 5y 20 7 eur 1 5y 51 8 eur 1 3y 49 9 eur 1 3y 49 > | cs |
In some case, it is convenient to keep orders of row and column until calculation is completed. But merge() function for joining data.frames delivers rearranged output with respect to key fields. To sidestep this rearranging effect, we make a user-defined function based on merge(), which preserves information of input x data. \(\blacksquare\)
You might like to look at the dplyr join functions. They preserve the order of rows and columns of the left data frame "as much as possible".
ReplyDeleteThank you very much for your suggestion.
DeleteI've heard that dplyr is a very useful and versatile R package.
I'll give it a try for the above-mentioned purpose.
You could simply start with adding an ID (or order, or...) column at the beginning in your dataframe X: X <- 1:9. Then, in the end, you can just sort your dataframe as per their ID number, and remove the ID column if you so please.
ReplyDeleteThank you for giving me useful advices.
DeleteI also use the similar approach as you said and add an additional column sorting.